



















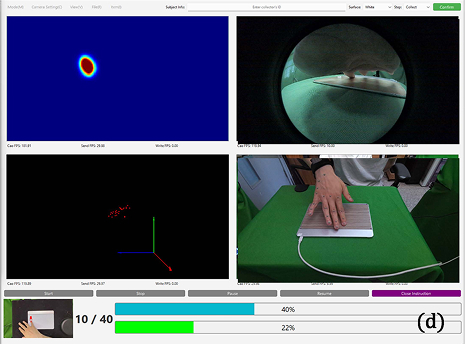





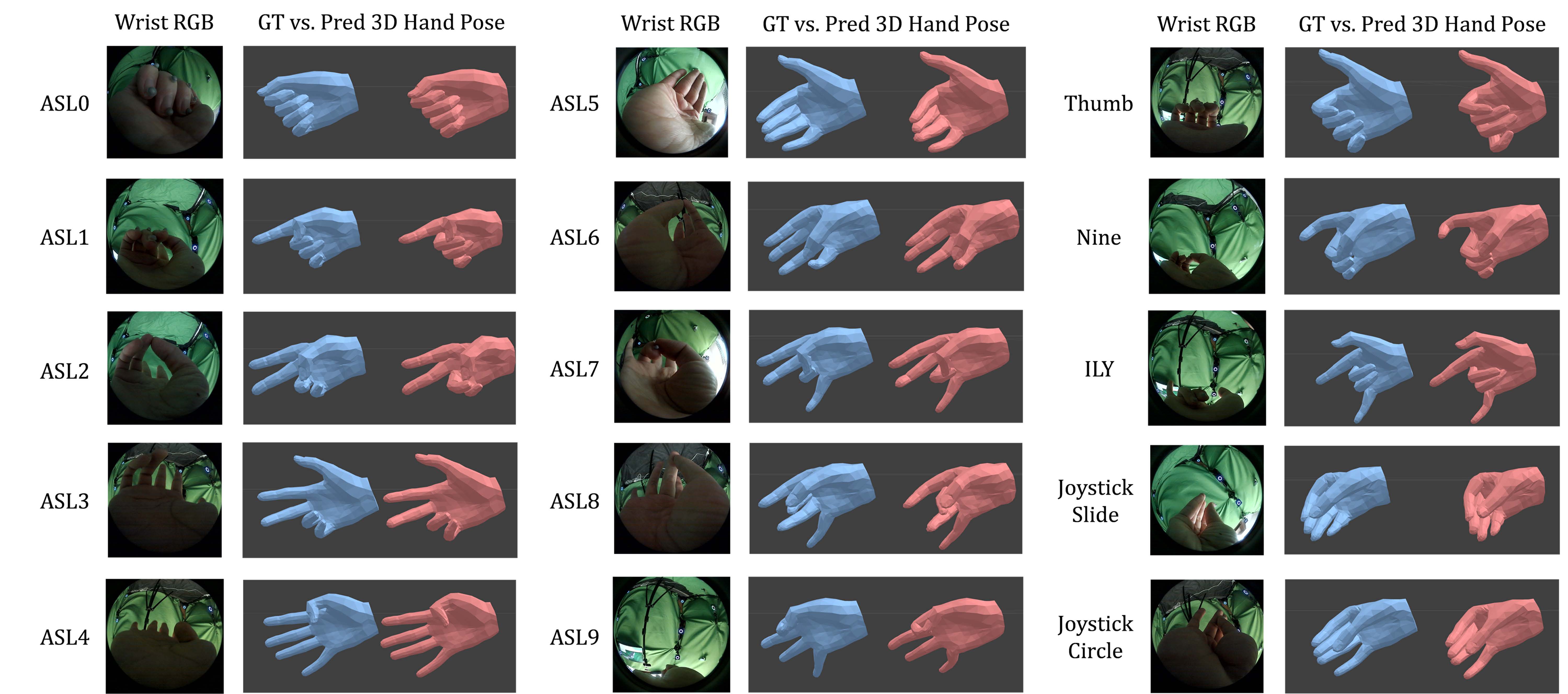
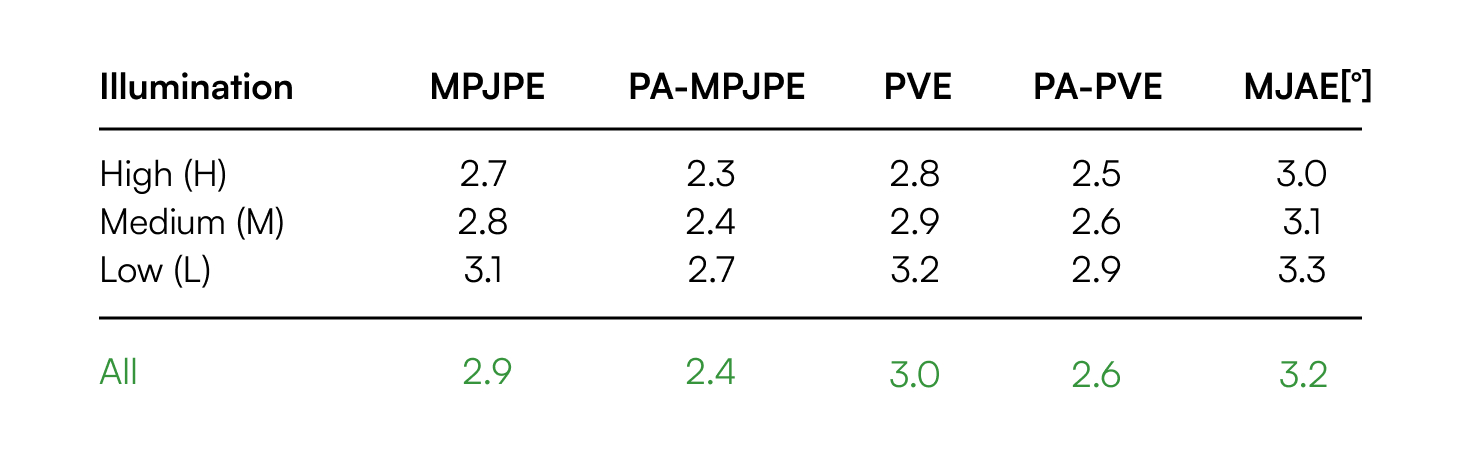
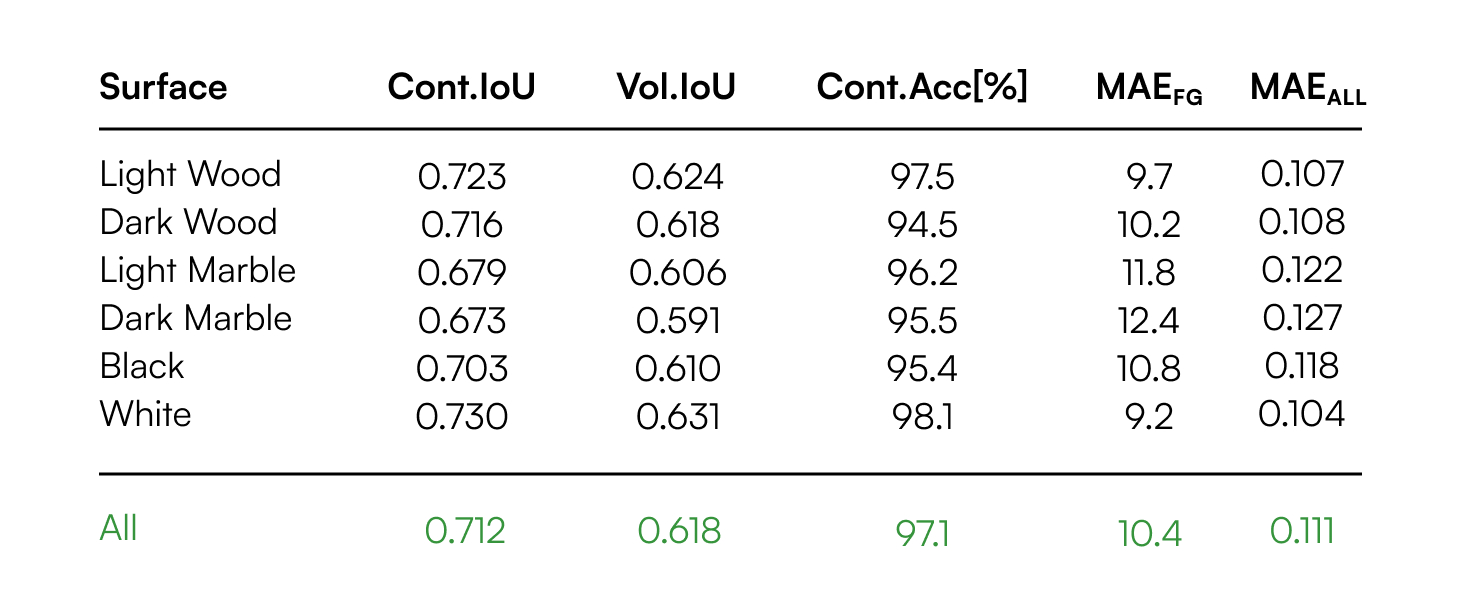
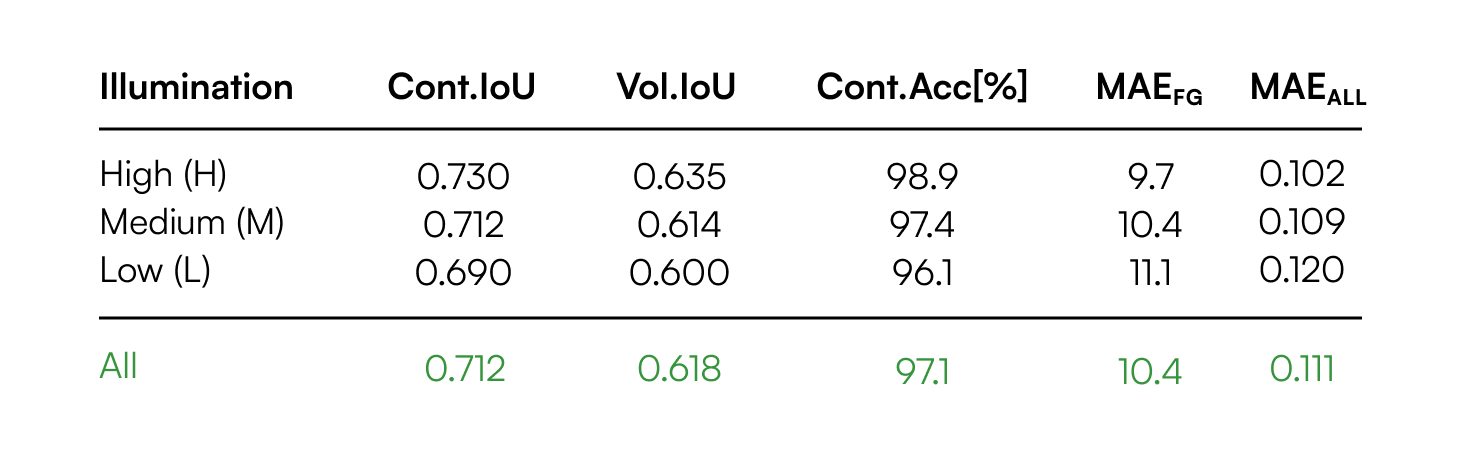
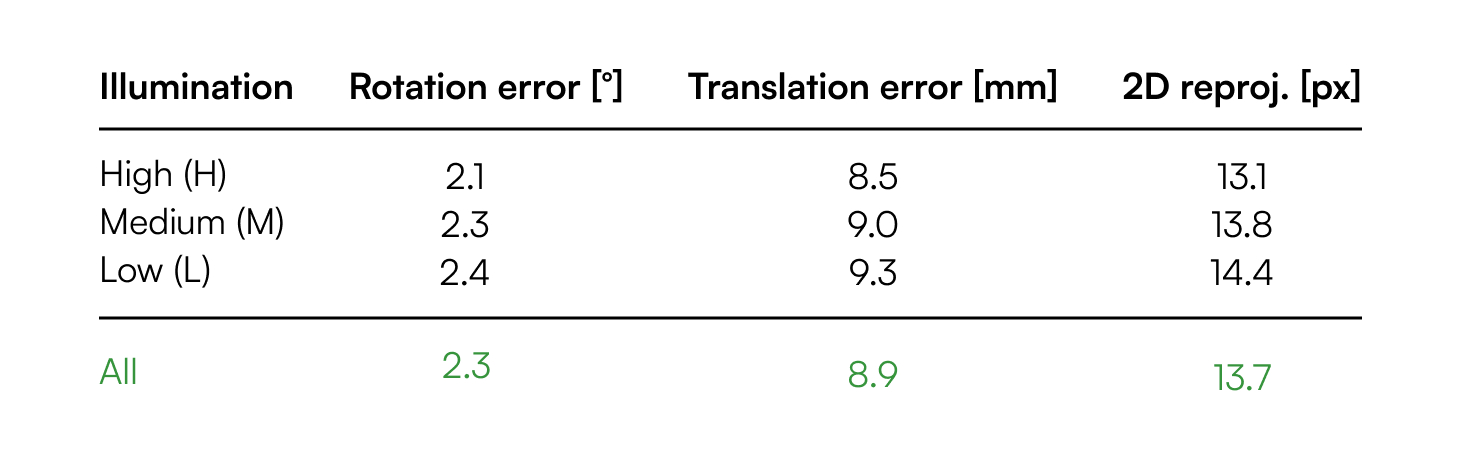
User Study:
Indoor scenarios (Study A)
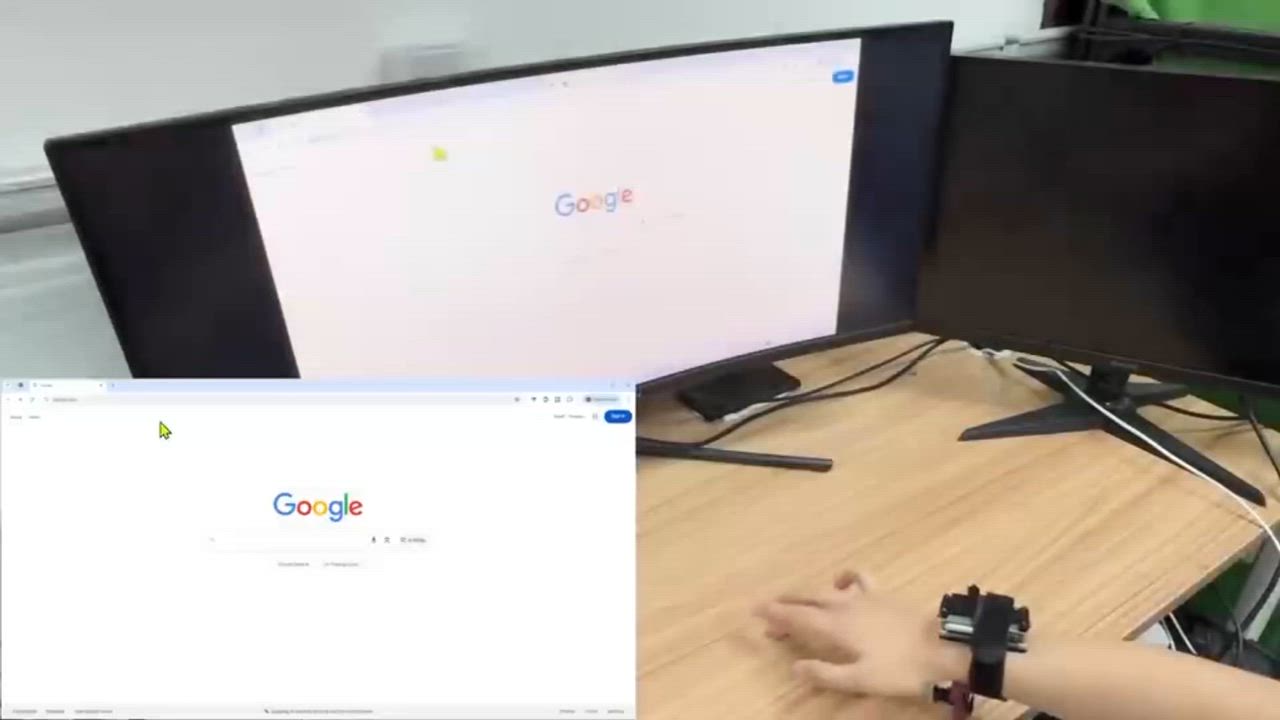
In three studies we conducted, we chose smartphone touchscreens as the baseline input method and compared PalmTrack with it. Smartphone touchscreens were selected because they provide absolute positioning capabilities and their screen size is comparable to that of a human hand.
In three studies we conducted, we chose smartphone touchscreens as the baseline input method and compared PalmTrack with it. Smartphone touchscreens were selected because they provide absolute positioning capabilities and their screen size is comparable to that of a human hand.
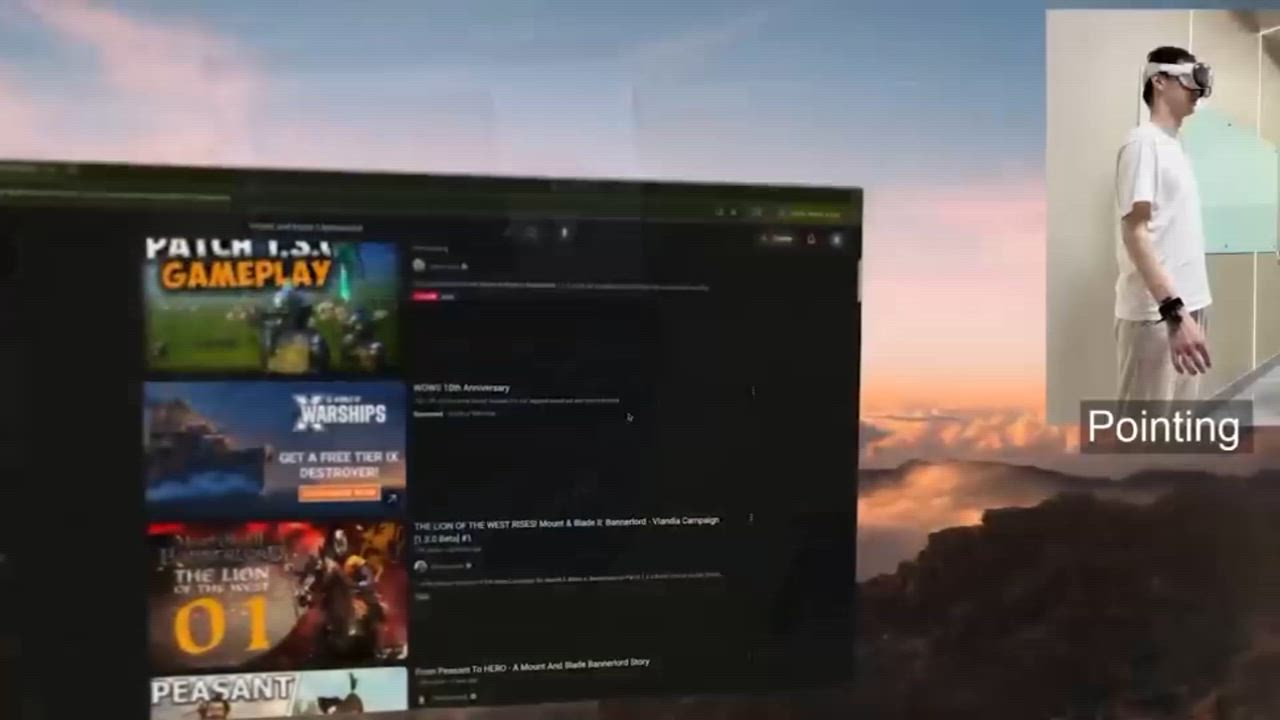
Study 1: Virtual Air Mouse (Mid-Air Pointing)
I validated the system's pointing precision using a standard Fitts’ Law task, where participants controlled a cursor via index finger position and performed clicks using a pinch gesture. The system achieved a throughput of 2.5 bits/s, matching the efficiency of a standard laptop touchpad and proving its viability as a precise, equipment-free input device for mid-air interaction.
I validated the system's pointing precision using a standard Fitts’ Law task, where participants controlled a cursor via index finger position and performed clicks using a pinch gesture. The system achieved a throughput of 2.5 bits/s, matching the efficiency of a standard laptop touchpad and proving its viability as a precise, equipment-free input device for mid-air interaction.
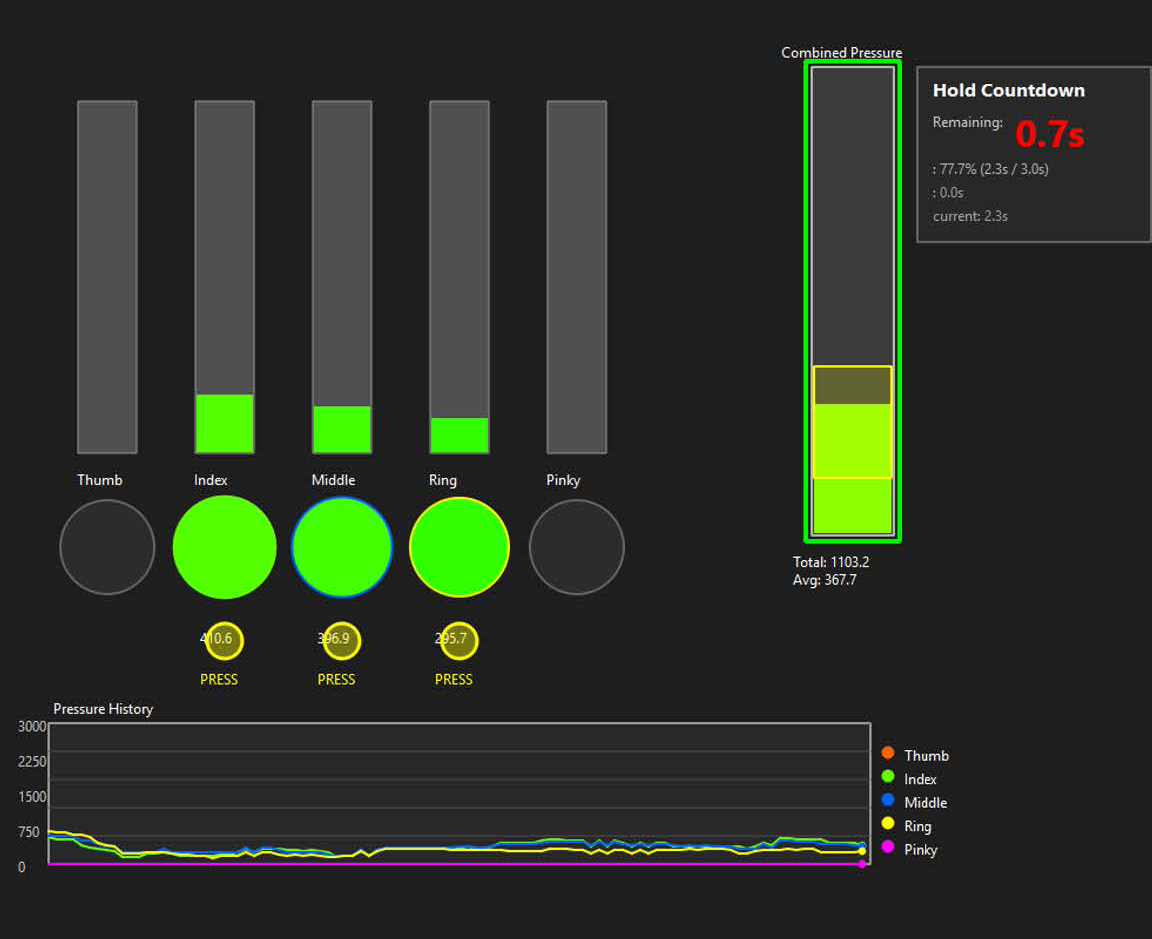
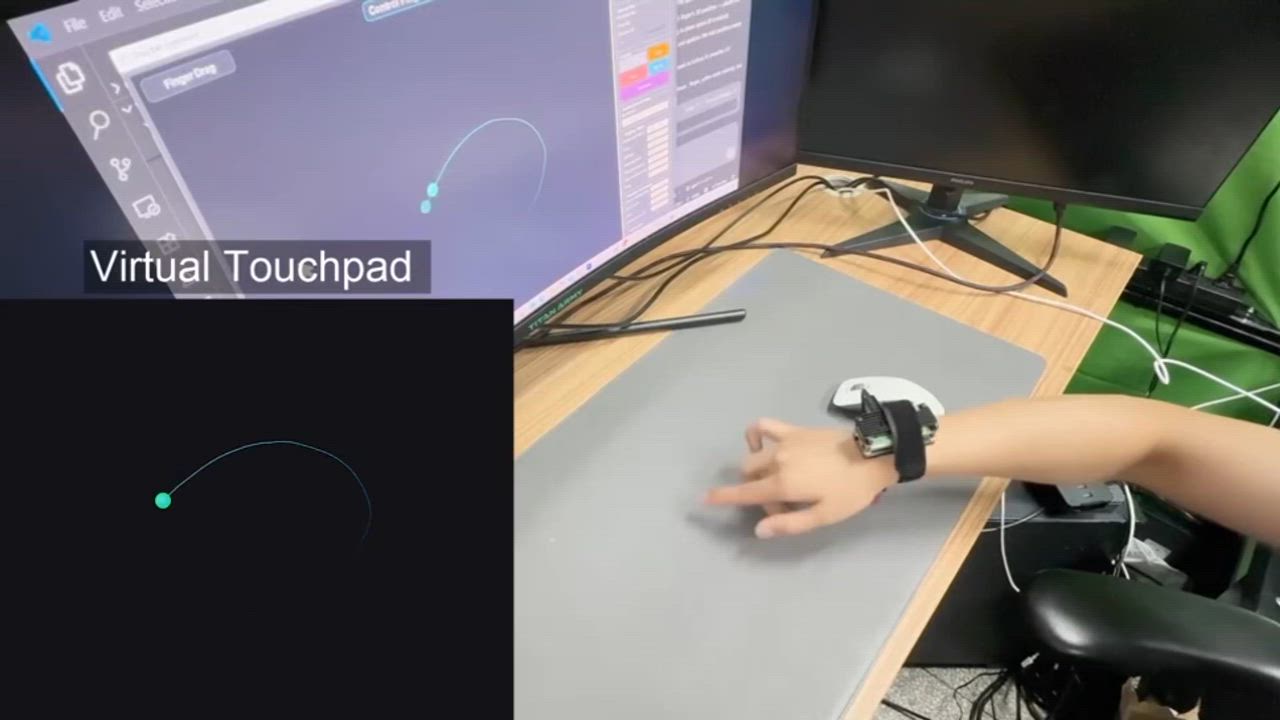
Study 3: Virtual Pressure-Sensitive Touchpad (Composite Interaction)
To simulate complex real-world workflows, we transformed a bare desktop into a virtual pressure-sensitive touchpad requiring simultaneous 2D dragging and precise vertical pressure holds. The system achieved an exceptional 98.0% success rate in this composite task, confirming it can reliably decouple pose tracking from pressure estimation to support stable, surface-agnostic control.
To simulate complex real-world workflows, we transformed a bare desktop into a virtual pressure-sensitive touchpad requiring simultaneous 2D dragging and precise vertical pressure holds. The system achieved an exceptional 98.0% success rate in this composite task, confirming it can reliably decouple pose tracking from pressure estimation to support stable, surface-agnostic control.
